
ARX is a comprehensive open source data anonymization tool aiming to provide scalability and usability.
 Florian Kohlmayer
c4768869c1
Initial implementation of d-presence
Florian Kohlmayer
c4768869c1
Initial implementation of d-presence
|
hace 9 años | |
|---|---|---|
| data | hace 9 años | |
| doc | hace 9 años | |
| lib | hace 9 años | |
| logo | hace 10 años | |
| src | hace 9 años | |
| .gitignore | hace 10 años | |
| LICENSE | hace 9 años | |
| build.xml | hace 9 años | |
| readme.md | hace 9 años |
readme.md
ARX - Powerful Data Anonymization
Introduction
ARX is an open source tool for transforming structured (i.e. tabular) sensitive personal data using selected methods from the broad area of statistical disclosure control. The basic idea is to transform datasets in ways that make sure that they adhere to well-known syntactic privacy criteria that mitigate attacks that may lead to privacy breaches. ARX can be used to remove direct identifiers (e.g. names) from datasets and to enforce further constraints on indirect identifiers. Indirect identifiers (or quasi-identifiers, or keys) are attributes that do not directly identify an individual but may together with other indirect identifiers form an identifier that can be used for linkage attacks. It is typically assumed that information about indirect identifiers is available to the attacker (in some form of background knowledge) and that they cannot simply be removed from the dataset (e.g. because they are required for analyses).
Three different types of privacy threats are commonly considered: membership disclosure means that an attacker is able to determine whether or not an individual is contained in a dataset utilizing quasi-identifying attributes. From this, additional personal information can potentially be inferred, e.g., if the data is from a cancer registry. Two additional types of disclosure deal with sensitive attributes. These are attributes in which an attacker might be interested and that, if disclosed, could cause harm to the data subject. Attribute disclosure means that an attacker is able to infer additional information about an individual without necessarily linking it to a specific item in a dataset. For example, the individual can be linked to a set of data items. This potentially allows inferring additional information, e.g., if all items share a certain sensitive attribute value. Identity disclosure means that an attacker can learn sensitive information about an individual by linking it to a specific data item, i.e., re-identifying the subject. This allows disclosing all information contained about the individual. More information is available here.
ARX can handle four different types of attributes. Identifiying attributes (such as name) can be removed from the dataset. Quasi-identifying attributes (such as age or zipcode) are transformed to meet formal privacy criteria. Sensitive attributes are kept as is but may be required to meet some privacy guarantees. Insensitive attributes are kept as is.
Methods
ARX implements a broad spectrum of methods, including (1) methods for analyzing re-identification risks, (2) methods for analyzing data utility, (3) syntactic privacy criteria and (4) methods for transforming data.
Re-identification risks may be analyzed based on sample characteristics or on the concept of uniqueness. Uniqueness can either be determined based on the sample itself or it may be estimated with super-population models. These statistical methods estimate characteristics of the overall population with probability distributions that are parameterized with sample characteristics. ARX provides default settings for populations, such as the USA, UK, France or Germany, and supports the methods by Pitman, Zayatz and the SNB model. ARX also implements the decision rule proposed and validated for clinical datasets by Dankar et al. More information can be found in this paper.
The utility of a dataset for a given usage scenario can be analyzed manually as well as automatically. For manual analysis, ARX implements methods from descriptive statistics. For automatic analysis of data utility, ARX employs so called utility metrics, which measure the loss of information induced by transformations. These methods enable ARX to completely classify the solution space and automatically determine the transformation with optimal data utility. As it may not always be possible to automatically determine the solution that best fits a user’s requirements, the classified solution space can be explored and alternative transformations can be analyzed. More information is available here.
ARX supports a broad spectrum of syntactic privacy criteria, including k-anonymity, ℓ-diversity, t-closeness and δ-presence. With implementations of classic k-anonymity as well as various variants of its extensions, ARX’s coverage of privacy criteria is unmatched. Variants of ℓ-diversity include recursive-(c,ℓ)-diversity, entropy-ℓ-diversity and distinct ℓ-diversity. The t-closeness criterion can be based on the earth mover’s distance with equal or hierarchical ground distance. k-Anonymity aims at preventing identity disclosure by countering linkage attacks. It basically defines an upper bound on the re-identification risk of individual data entries (over-) estimated with sample frequencies. ARX also supports several relaxed variants of this criterion, that enable risk-based anonymization. Firstly, a threshold on the average sample frequency may be used. Secondly, a threshold may be defined on the sample or population uniqueness, which can be estimated with super-population models. More information is available here.
For data transformation ARX implements a combination of generalization and suppression. For generalizing data items, the framework employs generalization hierarchies, which can easily be constructed by end-users to meet their requirements. The tool provides several methods for helping users with constructing such hierarchies. ARX implements combined support for two specific types of transformation methods: multi-dimensional global recording with full-domain attribute generalization and local recoding with tuple suppression. With tuple suppression, a subset of the data items is allowed to not adhere to the specified privacy criteria. During the anonymization process this subset is removed from the dataset, as long as the total number of suppressed tuples is lower than a user-defined threshold. This allows to further reduce information loss. This combination of methods is easy to understand by users and allows providing several advanced options for configuring and parameterizing the transformation process. For further information you may want to take a look at one of our presentations.
Highlights
ARX is not just a tool box, but a fully integrated application. ARX provides built-in data import facilities for relational databases (MS SQL, DB2, SQLite, MySQL), MS Excel and CSV files (all common formats, with auto-detection). ARX supports different data types and scales of measure, including strings (with nominal and ordinal scale), dates (interval scale), integers and decimals (ratio scale). Data types and formats of variables are automatically detected during data import. ARX can process low-quality data by handling missing and invalid values correctly in privacy models, transformation methods, visualizations and by supporting data cleansing during import and via manual removal of tuples with a query interface and a find & replace function. Generalization hierarchies can be represented in a functional manner, which allows support for categorical and continuous attributes (currently via categorization).
With its support of basic k-anonymity and multiple variants of its extensions as well as risk-based anonymization methods, ARX’s support of privacy criteria is not matched by any other software. The tool also supports arbitrary combinations of the implemented privacy criteria.
ARX is highly scalable and can handle very large datasets (several million data entries) on commodity hardware. This is due to a dedicated in-memory data management engine, that has been carefully engineered to meet the needs of data anonymization algorithms. It works with compressed data representations, implements a tight coupling between transformation operators and the „database kernel” and also provides a space-time trade-off that can be configured by users. More details are available here. On top of this framework, ARX uses an optimized search strategy that exploits multiple pruning strategies. More details are available here. In most cases, this approach outperforms previous methods by up to several orders of magnitude. It is able to find optimal solutions for monotonic and non-monotonic privacy criteria and utility metrics (e.g. for ℓ-diversity, t-closeness and δ-presence with tuple suppression). Because of its scalability, ARX enables users to explore a large number of possible privacy-preserving transformations in near real-time and pick the one that best suits their needs (i.e. a specific usage scenario).
A clean API brings data anonymization capabilities to any Java program. A comprehensive graphical user interface (GUI) is oriented towards end-users and provides several advanced features, such as a wizard for creating generalization hierarchies, an intuitive way to explore the solution space and ways to assess the utility of transformed datasets. The cross-platform GUI (Windows, Linux/GTK, OSX) provides native interfaces and is available as a binary distributions with installers. ARX provides backwards compatibility to all previous releases. You may want to take a look at the downloads section.
Anonymization workflow
The biggest challenge in data anonymization is to achieve a balance between data utility and privacy. ARX models many different aspects of this balancing process. Methods are combined into a multi-step workflow that allows users to iteratively adjust parameters, until the result matches their requirements. As depicted in the below figure, the basic steps consist of 1) configuring the transformation process, 2) exploring the solution space and 3) analyzing input and output data. In the configuration phase, input data is loaded, generalization hierarchies are imported or created and all further parameters, such as privacy criteria, are specified.
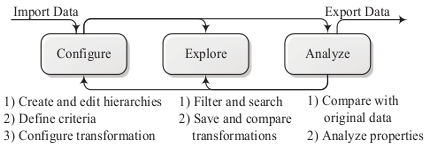
When the solution space has been characterized by executing the anonymization algorithm, the exploration phase allows searching the solution space for privacy-preserving data transformations that fulfill a user’s requirements. To assess suitability, the analysis phase allows comparing transformed datasets to the original input dataset. Moreover, datasets may be analyzed regarding re-identification risks. Based on these analyses, further solution candidates might be considered and analyzed, or the configuration of the anonymization process might be altered. For further information you may want to take a look at one of our presentations or our manual.
Examples
ARX Anonymization Tool
The graphical anonymization tool provides an intuitive interface for end-users and implements advanced features, such as wizards and a context-sensitive help. Wizards support users in creating transformation rules, selecting data types, performing data cleansing and in querying the dataset. The solution space is visualized in different ways: (1) directly, as a mathematical structure called lattice, (2) indirectly, as a list or, (3) as a set of tiles. Summary statistics, distribution of values and contingencies are displayed in graphical plots. Similar visualizations are provided for various aspects risk analyses.
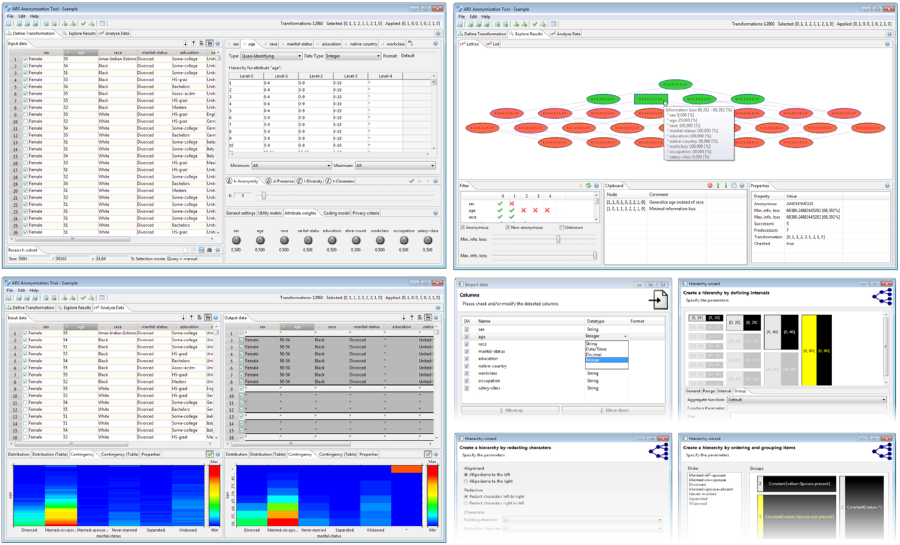
ARX’s graphical user interface supports the three steps from the anonymization process described in the previous section by implementing four dedicated perspectives. A manual can be found here. For further information you may want to take a look at one of our presentations.
ARX Software Library
The Java software library offers a carefully designed API for seamless integration into other systems. It provides full access to all features implemented in the ARX anonymization framework.
// Load data
Data data = Data.create("input.csv");
// Set attribute types and load hierarchies
data.getDefinition().setAttributeType("age", Hierarchy.create("age.csv"));
data.getDefinition().setAttributeType("zipcode", Hierarchy.create("zipcode.csv"));
data.getDefinition().setAttributeType("disease", AttributeType.SENSITIVE_ATTRIBUTE);
// Define privacy requirements
ARXConfiguration config = ARXConfiguration.create();
config.addCriterion(new KAnonymity(5));
config.addCriterion(new HierarchicalDistanceTCloseness("disease", 0.6d, Hierarchy.create("disease.csv")));
config.setMaxOutliers(0d);
config.setMetric(Metric.createEntropyMetric());
// Perform anonymization
ARXAnonymizer anonymizer = new ARXAnonymizer();
ARXResult result = anonymizer.anonymize(data, config);
// Write result
result.getHandle().write("output.csv");
More examples are also available in the repository.
Limitations
ARX is an open source tool for transforming structured (i.e. tabular) sensitive personal data. ARX is not:
- A tool for masking identifiers in unstructured data. For such methods, you may want to take a look at MIST, MITdeid or the NLM Scrubber.
- A tool for privacy-preserving data analysis in an interactive scenario. For such methods, you may want to take a look at AirCloak, Airavat, Fuzz, PINQ or HIDE.
Specific limitations
- ARX implements in-memory data management, meaning that the dataset that is to be anonymized must fit into a machine's main memory. This should normally not be a problem, as ARX can handle datasets with several million entries on current commodity hardware. For very large datasets, memory consumption may be reduced by removing attributes that are insensitive and irrelevant to the anonymization process. If these must be re-integrated after the de-identification process, a tuple identifier can be introduced. Moreover, ARX implements a space-time trade-off that may be used to reduce memory consumption.
- ARX currently relies on a globally-optimal search strategy and materializes the complete solution space. As a consequence, it can only handle anonymization problems in which the search space is small enough to allow materialization. As a rule of thumb ARX can handle datasets with up to ~15 quasi-identifiers, but this depends on the size of the generalization hierarchies utilized. In the near future ARX will be extended with methods that overcome this limitation.
General limitations
- Data anonymization is a complex issue that must be performed by experts. There is no single measure that is able to protect datasets from all possible threats, especially not while being flexible enough to support all usage scenarios. As is common in IT security, data controllers should therefore follow the "onion layer principle" and employ a multitude of measures for protecting sensitive personal data. This includes legal agreements as well as "data economy", meaning the principle that nothing more than those details may be collected, stored and shared which are absolutely essential.
- The anonymization techniques implemented by ARX can be an important building block for protecting sensitive personal data, but they can only provide very specific guarantees which require rather strong assumptions to be made about the goals and the background knowledge of an attacker. Alternative methods, such as Differential Privacy, require much less such assumptions but usually involve stronger trade-offs in terms of utility or supported workflows.
Website
More information can be found on our website at: http://arx.deidentifier.org/
License
The ARX framework is copyright (C) 2012-2015 Florian Kohlmayer and Fabian Prasser. It is licensed under the Apache License, Version 2.0:
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
External Libraries
The framework uses external libraries. The according licenses are listed in the respective lib folders.